
Bonjour à vous, pionniers de l’IA ! Aujourd’hui, nous allons plonger dans un concept fondamental de la manipulation des données textuelles : la tokenisation.
Ce processus, bien que souvent négligé, est essentiel pour préparer les données textuelles à une variété de tâches de traitement du langage naturel (NLP). La tokenisation ne concerne pas seulement la blockchain et constitue la première étape de toute analyse textuelle et est cruciale pour la compréhension et la manipulation des données linguistiques.
Alors, êtes-vous prêts à explorer ce monde fascinant où chaque mot compte ? Que l’aventure commence !
Qu’est-ce que la Tokenisation ?
La tokenisation est le processus de décomposition d’un texte en unités plus petites appelées “tokens”. Ces tokens peuvent être des mots, des phrases, ou même des sous-parties de mots, en fonction de la méthode de tokenisation utilisée.
Pourquoi est-ce une étape importante pour le traitement du langage ?
La tokenisation permet aux modèles de traitement du langage naturel de comprendre et de manipuler le texte. Sans ce processus, les modèles seraient incapables de traiter efficacement les données textuelles, car ils ne sauraient pas où commence et où finit chaque mot ou phrase. La précision et l’efficacité de nombreuses applications NLP dépendent de la qualité de la tokenisation.

Quelles sont les différents types de Tokenisation ?
Il existe plusieurs approches pour la tokenisation, chacune ayant ses avantages et ses inconvénients. Les méthodes les plus courantes incluent :
- Tokenisation basée sur les mots : La méthode la plus simple, où le texte est divisé en mots individuels. Par exemple, “Bonjour à tous” serait tokenisé en [“Bonjour”, “à”, “tous”].
- Tokenisation basée sur les caractères : Ici, le texte est décomposé en caractères individuels. Par exemple, “Bonjour” deviendrait [“B”, “o”, “n”, “j”, “o”, “u”, “r”].
- Tokenisation basée sur les sous-mots : Cette méthode décompose le texte en unités plus petites que les mots, mais plus grandes que les caractères. Elle est souvent utilisée dans les modèles de langage modernes comme BERT et GPT. Par exemple, “Bonjour” pourrait être décomposé en [“Bon”, “jour”].
- Tokenisation basée sur les phrases : Le texte est décomposé en phrases ou segments plus grands. Cette méthode est utile pour des tâches où la compréhension du contexte de phrase est cruciale.
Les techniques de Tokenisation
1. La tokenisation basée sur les espaces

La méthode la plus intuitive et simple, cette approche consiste à diviser le texte en utilisant les espaces comme délimiteurs. Bien qu’efficace pour les textes en anglais, elle peut être moins performante pour les langues avec des systèmes d’écriture différents, comme le chinois ou le japonais.
Par exemple :
texte = "Bonjour à tous"
tokens = texte.split()
print(tokens)
# Sortie: ['Bonjour', 'à', 'tous']2. La tokenisation par expressions régulières (Regex)

Les expressions régulières (regex) offrent une flexibilité accrue pour définir des règles de tokenisation. Cela permet de gérer des cas plus complexes comme la ponctuation et les contractions.
Par exemple :
import re
texte = "Bonjour, comment ça va?"
tokens = re.findall(r'\\\\b\\\\w+\\\\b', texte)
print(tokens)
# Sortie: ['Bonjour', 'comment', 'ça', 'va']
3. La tokenisation à l’aide de bibliothèques

Les bibliothèques de NLP comme NLTK et SpaCy fournissent des outils puissants pour la tokenisation, offrant des solutions optimisées et prêtes à l’emploi.
Par exemple avec la bibliothèque NLTK :
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
texte = "Bonjour à tous!"
tokens = word_tokenize(texte)
print(tokens)
# Sortie: ['Bonjour', 'à', 'tous', '!']
Par exemple avec la bibliothèque SpaCy :
import spacy
nlp = spacy.load('fr_core_news_sm')
texte = "Bonjour à tous!"
doc = nlp(texte)
tokens = [token.text for token in doc]
print(tokens)
# Sortie: ['Bonjour', 'à', 'tous', '!']
Vous pouvez également rencontrer la bibliothèque Gensim qui est aussi très populaire et que nous vous recommandons.4. La tokenisation basée sur des dictionnaires

Cette technique utilise des dictionnaires de mots pour la tokenisation. Elle est particulièrement utile pour les langues ayant des structures de mots complexes comme le chinois, où les mots ne sont pas séparés par des espaces.
Par exemple :
from jieba import cut
texte = "我喜欢学习人工智能"
tokens = list(cut(texte))
print(tokens)
# Sortie: ['我', '喜欢', '学习', '人工智能']
5. La tokenisation par Subwords
Les méthodes de tokenisation par subwords, comme Byte Pair Encoding (BPE) et WordPiece, sont devenues populaires avec l’avènement de modèles de langage pré-entraînés comme BERT et GPT. Ces méthodes permettent de gérer efficacement les mots inconnus et de réduire le vocabulaire nécessaire.
Byte Pair Encoding (BPE) :

BPE commence avec un vocabulaire de caractères et fusionne les paires de caractères les plus fréquentes pour former de nouvelles unités jusqu’à ce qu’un certain seuil soit atteint.
Par exemple :
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.pre_tokenizers import Whitespace
tokenizer = Tokenizer(BPE())
tokenizer.pre_tokenizer = Whitespace()
trainer = BPETrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
tokenizer.train(["path/to/dataset.txt"], trainer)
output = tokenizer.encode("Bonjour à tous")
print(output.tokens)
# Sortie: ['Bon', 'jour', 'à', 'tous']
WordPiece :

Similaire à BPE, WordPiece utilise un algorithme pour construire un vocabulaire de sous-mots basé sur la fréquence des paires de caractères dans le corpus d’entraînement.
Par exemple :
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
tokens = tokenizer.tokenize("Bonjour à tous")
print(tokens)
# Sortie: ['bon', '##jour', 'à', 'tous']
6. La tokenisation contextuelle

Les modèles modernes de NLP comme BERT et GPT utilisent des approches contextuelles pour la tokenisation, permettant au modèle de comprendre les tokens en fonction de leur contexte dans la phrase. Cela améliore considérablement la performance sur des tâches comme la reconnaissance d’entités nommées et l’analyse syntaxique.
Par exemple :
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
texte = "Tokenization is essential for NLP tasks."
tokens = tokenizer.tokenize(texte)
print(tokens)
# Sortie: ['Token', '##ization', 'is', 'essential', 'for', 'NL', '##P', 'tasks', '.']
Les défis rencontrer lors de la tokenisation
La tokenisation n’est pas sans défis. Différentes langues et contextes posent des problèmes uniques :
- Toutes les langues agglutinantes :
Les langues comme le turc et le finnois, où les mots peuvent être extrêmement longs et composés de plusieurs morphèmes, rendent la tokenisation beaucoup plus complexe. - L’ambiguïté :
Les mots ayant plusieurs significations ou les phrases sans ponctuation peuvent créer des ambiguïtés. Par exemple, “Il est temps de manger, enfants” vs “Il est temps de manger enfants”. - La ponctuation et les symboles :
Les symboles spéciaux, la ponctuation, et les contractions peuvent compliquer la tokenisation. Par exemple, “l’école” doit être tokenisé différemment selon le contexte. - Émoticônes et symboles modernes :
Avec l’usage croissant des émoticônes et autres symboles modernes dans la communication numérique, la tokenisation doit s’adapter pour les gérer correctement.
Les meilleures pratiques pour la Tokenisation
1. Subword Tokenization (BPE, WordPiece)
Les méthodes de tokenisation par sous-mots comme Byte Pair Encoding (BPE) et WordPiece sont devenues populaires avec l’avènement de modèles de langage pré-entraînés comme BERT et GPT. Ces méthodes permettent de gérer efficacement les mots inconnus et de réduire le vocabulaire nécessaire.
Byte Pair Encoding (BPE) :
La méthode BPE commence avec un vocabulaire de caractères et fusionne les paires de caractères les plus fréquentes pour former de nouvelles unités jusqu’à ce qu’un certain seuil soit atteint.
Par exemple :
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.pre_tokenizers import Whitespace
tokenizer = Tokenizer(BPE())
tokenizer.pre_tokenizer = Whitespace()
trainer = BPETrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
tokenizer.train(["path/to/dataset.txt"], trainer)
output = tokenizer.encode("Bonjour à tous")
print(output.tokens)
# Sortie: ['Bon', 'jour', 'à', 'tous']
WordPiece :
Similaire à la méthode BPE, WordPiece utilise un algorithme pour construire un vocabulaire de sous-mots basé sur la fréquence des paires de caractères dans le corpus d’entraînement.
Par exemple :
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
tokens = tokenizer.tokenize("Bonjour à tous")
print(tokens)
# Sortie: ['bon', '##jour', 'à', 'tous']
2. SentencePiece
SentencePiece est une méthode de tokenisation basée sur les sous-mots qui ne nécessite pas de segmentation préalable du texte, ce qui la rend particulièrement utile pour les langues sans espaces comme le chinois ou le japonais.
Par exemple :
import sentencepiece as spm
spm.SentencePieceTrainer.train('--input=path/to/dataset.txt --model_prefix=m --vocab_size=5000')
sp = spm.SentencePieceProcessor()
sp.load('m.model')
tokens = sp.encode_as_pieces('Bonjour à tous')
print(tokens)
# Sortie: ['▁Bonjour', '▁à', '▁tous']
Exemples d’utilisations des tokeniser
1. Pour l’analyse de sentiments
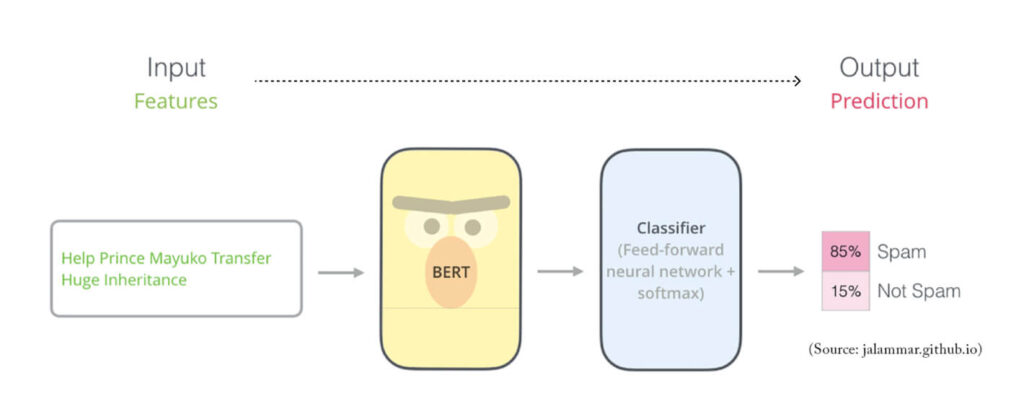
La tokenisation est une étape cruciale dans l’analyse de sentiments, où chaque mot (token) est analysé pour déterminer le ton et l’émotion du texte. Cette analyse permet de capter les sentiments positifs, négatifs ou neutres exprimés dans les données textuelles. Les entreprises utilisent ces informations pour comprendre les réactions des consommateurs, analyser les sentiments du marché et suivre les opinions publiques sur les médias sociaux.
Par exemple :
pythonCopier le code
from textblob import TextBlob
texte = "Je suis très heureux aujourd'hui!"
blob = TextBlob(texte)
sentiment = blob.sentiment
print(sentiment)
# Sortie: Sentiment(polarity=0.8, subjectivity=1.0)Les meilleurs modèles pour l’analyse de sentiment
- RoBERTa : Utilisé pour ses performances robustes sur diverses tâches de NLP, y compris l’analyse de sentiments.
- DistilBERT : Une version plus légère de BERT qui offre un bon équilibre entre vitesse et précision.
2. Pour la traduction automatique
Les systèmes de traduction automatique utilisent la tokenisation pour décomposer les phrases et les traduire mot par mot ou phrase par phrase. Cette technique permet de gérer des traductions précises et fluides, essentielles pour les applications multilingues.
Par exemple :
pythonCopier le code
from transformers import MarianMTModel, MarianTokenizer
model_name = 'Helsinki-NLP/opus-mt-fr-en'
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
texte = "Bonjour, comment ça va?"
tokens = tokenizer.prepare_seq2seq_batch([texte], return_tensors='pt')
translation = model.generate(**tokens)
translated_text = tokenizer.decode(translation[0], skip_special_tokens=True)
print(translated_text)
# Sortie: "Hello, how are you?"
Les meilleurs modèles pour la traduction automatique
- MarianMT : Spécialement conçu pour la traduction automatique, offrant des modèles pour plusieurs paires de langues.
- M2M-100 : Un modèle de Facebook AI qui prend en charge la traduction directe entre 100 langues sans passer par l’anglais comme langue intermédiaire.
3. Systèmes de question-réponse
Les systèmes de question-réponse dépendent fortement de la tokenisation pour comprendre la question et extraire les réponses pertinentes du texte. Ces systèmes sont utilisés dans les assistants virtuels, les services clientèle automatisés et les moteurs de recherche pour fournir des réponses précises et pertinentes.
Par exemple :
pythonCopier le code
from transformers import pipeline
qa_pipeline = pipeline('question-answering')
context = "La tokenisation est le processus de décomposition du texte en unités plus petites appelées tokens."
question = "Qu'est-ce que la tokenisation?"
result = qa_pipeline(question=question, context=context)
print(result['answer'])
# Sortie: "le processus de décomposition du texte en unités plus petites appelées tokens"
Les meilleurs modèles pour vos chatbots Q/R
- BERT : Le modèle de base pour de nombreuses applications de question-réponse.
- ALBERT : Une version allégée de BERT avec des paramètres réduits et des performances améliorées.
4. Résumé Automatique
La tokenisation est essentielle pour les systèmes de résumé automatique, qui réduisent un texte à ses points essentiels tout en préservant sa signification. Cela est particulièrement utile pour digérer rapidement de grandes quantités d’informations.
Par exemple :
pythonCopier le code
from transformers import PegasusTokenizer, PegasusForConditionalGeneration
model_name = "google/pegasus-xsum"
tokenizer = PegasusTokenizer.from_pretrained(model_name)
model = PegasusForConditionalGeneration.from_pretrained(model_name)
texte = "La tokenisation est le processus de décomposition du texte en unités plus petites appelées tokens. Elle est essentielle pour la compréhension et la manipulation des données textuelles."
tokens = tokenizer(texte, truncation=True, padding='longest', return_tensors="pt")
summary = model.generate(**tokens)
summary_text = tokenizer.decode(summary[0], skip_special_tokens=True)
print(summary_text)
# Sortie: "La tokenisation décompose le texte en unités plus petites appelées tokens."
Les meilleurs générateurs de token pour faire des résumés automatiques
- PEGASUS : Conçu spécifiquement pour le résumé de texte avec des performances exceptionnelles sur les benchmarks de résumé.
- BART : Un modèle bidirectionnel et autoregressif qui excelle dans la génération de texte et le résumé automatique.
5. Classification de texte
La tokenisation prépare le texte pour des tâches de classification, telles que la catégorisation des courriels en spam ou non-spam, ou l’identification de sujets dans des documents. Cette technique est couramment utilisée dans les filtres de spam, la modération de contenu et l’organisation de documents.
Par exemple :
pythonCopier le code
from transformers import BertTokenizer, BertForSequenceClassification
import torch
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name)
texte = "This is a spam message"
tokens = tokenizer(texte, return_tensors='pt')
output = model(**tokens)
predictions = torch.nn.functional.softmax(output.logits, dim=-1)
print(predictions)
# Sortie: tensor([[0.01, 0.99]])
Les meilleurs générateurs de token pour faire de la classification
- BERT : Toujours l’un des meilleurs pour la classification de texte.
- XLNet : Un modèle autoregressif qui surpasse BERT sur certaines tâches de classification.
6. Détection d’Entités Nommées
La tokenisation est utilisée pour identifier et extraire des entités nommées comme les noms de personnes, les lieux, et les dates dans un texte. Cette tâche est cruciale pour des applications telles que l’extraction d’informations, la recherche d’information et la gestion des connaissances.
Par exemple :
pythonCopier le code
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name = "dbmdz/bert-large-cased-finetuned-conll03-english"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
texte = "Hugging Face Inc. is a company based in New York City."
entities = nlp(texte)
print(entities)
# Sortie: [{'entity': 'I-ORG', 'score': 0.99, 'index': 1, 'start': 0, 'end': 12, 'word': 'Hugging Face Inc.'}, {'entity': 'I-LOC', 'score': 0.99, 'index': 10, 'start': 35, 'end': 47, 'word': 'New York City.'}]
Les meilleurs générateurs de tokens pour détécter les entités nommées
- SpaCy : Une bibliothèque légère mais puissante pour les tâches de NER.
- Flair : Connu pour ses représentations contextuelles de caractères qui améliorent la détection des entités nommées.
7. Correction grammaticale
Les systèmes de correction grammaticale utilisent la tokenisation pour analyser la structure des phrases et proposer des corrections. Cette technologie est largement utilisée dans les outils d’écriture assistée pour améliorer la qualité du texte.
Par exemple :
pythonCopier le code
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_name = "t5-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
texte = "This are a example of a grammatic error."
input_text = "correct: " + texte
tokens = tokenizer(input_text, return_tensors='pt')
correction = model.generate(**tokens)
corrected_text = tokenizer.decode(correction[0], skip_special_tokens=True)
print(corrected_text)
# Sortie: "This is an example of a grammatical error."
Les meilleurs générateurs de token pour faire de la correction de grammaire
- T5 : Utilisé pour de nombreuses tâches de génération de texte, y compris la correction grammaticale.
- Grammarly : Utilise des modèles propriétaires avancés pour la correction grammaticale et le style d’écriture.
8. Génération de texte
La tokenisation est cruciale pour les modèles de génération de texte, qui créent de nouveaux contenus basés sur des prompts donnés. Cette capacité est utilisée dans des applications allant de la rédaction créative aux chatbots en passant par la génération de code.
Par exemple :
pythonCopier le code
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model_name = "gpt2"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
prompt = "Once upon a time"
tokens = tokenizer.encode(prompt, return_tensors='pt')
generated = model.generate(tokens, max_length=50)
generated_text = tokenizer.decode(generated[0], skip_special_tokens=True)
print(generated_text)
# Sortie: "Once upon a time, in a land far away, there lived a young prince who dreamed of becoming a great knight. He spent his days..."
Les meilleurs générateurs de token pour générer du texte
- GPT-4o : Le modèle de génération de texte de pointe, capable de produire des textes de haute qualité dans divers styles et contextes.
- Jurassic-1 : Un modèle de génération de texte concurrent de GPT-3 avec des capacités similaires et des performances impressionnantes.
La tokenisation est un processus fondamental dans le traitement du langage naturel, transformant le texte brut en unités exploitables par les modèles de machine learning. Que ce soit pour des tâches simples comme l’analyse de texte ou des applications avancées comme la traduction automatique et les systèmes de question-réponse, la tokenisation joue un rôle crucial dans la réussite des projets NLP.
En comprenant les différentes techniques de tokenisation et leurs applications, vous êtes désormais mieux équipés pour tirer parti de ces méthodes dans vos propres projets. La tokenisation, bien que souvent invisible, est la clé qui ouvre la porte à une compréhension et une manipulation efficace des données textuelles. Alors, continuez à explorer et à innover dans ce domaine fascinant du traitement du langage naturel. Que votre aventure en tokenisation commence maintenant !