
Bonjour à vous, passionnés de l’intelligence artificielle ! Si vous lisez ceci, c’est probablement parce que vous êtes captivé par le potentiel incroyable du Traitement du Langage Naturel (NLP) et que vous souhaitez approfondir vos connaissances dans ce domaine fascinant.
Imaginez un monde où les machines comprennent et interprètent le langage humain de manière fluide, où elles peuvent converser, traduire, résumer et même générer du texte comme nous le faisons. Accrochez-vous, car nous allons explorer ensemble cet univers captivant du NLP.
Qu’est-ce que le traitement automatique du langage naturel ?
Le Traitement Automatique du Langage Naturel (TALN), ou NLP, est une branche de l’intelligence artificielle (IA) qui se concentre sur l’interaction entre les ordinateurs et les humains par le biais du langage naturel. Le but ultime du NLP est de permettre aux machines de comprendre, interpréter et générer le langage humain de manière à ce qu’il soit à la fois utile et naturel.
Un peu d’histoire sur les NLP pour comprendre
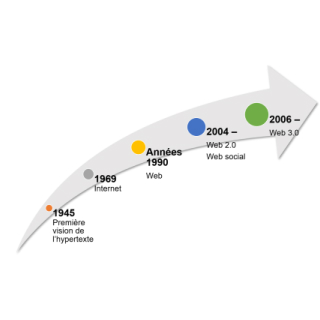
Les débuts du NLP remontent aux années 1950 avec les premières tentatives de traduction automatique. L’évolution du NLP a été marquée par plusieurs étapes importantes, notamment :
- Années 1950-1960 : Les premiers systèmes de traduction automatique et de traitement de texte simple.
- Années 1970-1980 : Introduction des grammaires formelles et des parsers syntaxiques.
- Années 1990 : Explosion des données numériques et développement des techniques d’apprentissage statistique.
- Années 2000 : Avènement des algorithmes d’apprentissage profond (deep learning) et des réseaux de neurones récurrents (RNN).
- Depuis 2010 : Utilisation des transformeurs (transformers) et des modèles de langage étendus (LLM) comme GPT, BERT, et leurs descendants.

Début du NLP
Premières tentatives de traduction automatique.
-
Grammaires Formelles et Parsing
Développement des parsers syntaxiques.
-
Montée du Machine Learning
Utilisation des techniques d'apprentissage statistique.
Révolution du Deep Learning
Adoption des réseaux de neurones récurrents (RNN).
Que fait-on avec le traitement du language naturel ?
Le NLP a une multitude d’applications dans divers domaines, notamment :
- Assistants virtuels : Siri, Alexa, Google Assistant.
- Traduction automatique : Google Translate, DeepL.
- Analyse de sentiment : Outils pour déterminer le ton et l’émotion dans des textes.
- Génération de texte : Modèles comme GPT-3 pour la création de contenu.
- Résumé automatique : Techniques pour condenser de longues pièces de texte en résumés courts.
- Reconnaissance vocale : Conversion de la parole en texte.
- Systèmes de recommandation : Analyse des avis clients pour recommander des produits.
Les concepts que vous devez maîtriser pour devenir un expert du traitement du langage
Pour plonger dans le monde du NLP, il est crucial de se familiariser avec certains concepts clés. Nous allons explorer ici les fondations de notions bien plus complexes. Rassurez-vous, nous ne nous arrêterons pas aux bases !
Si vous êtes vraiment passionné, nous vous invitons à aller encore plus loin dans les sections avancées. Préparez-vous à un voyage fascinant à travers le NLP !
1. La tokenisation
La tokenisation est le processus de division d’un texte en unités plus petites appelées “tokens”. Les tokens peuvent être des mots, des phrases ou même des caractères, selon le niveau de granularité souhaité.
Prenons la phrase : “Bonjour, comment ça va ?”. La tokenisation de cette phrase pourrait produire les tokens suivants : [“Bonjour”, “,”, “comment”, “ça”, “va”, “?”].
2. L’étiquetage Part-Of-Speech (POS)
L’étiquetage POS consiste à attribuer à chaque token une étiquette indiquant sa catégorie grammaticale (verbe, nom, adjectif, etc.). Cette étape est cruciale pour comprendre la structure syntaxique du texte.
Pour la phrase “Le chat mange une souris”, les étiquettes POS pourraient être : [(“Le”, “DET”), (“chat”, “NOUN”), (“mange”, “VERB”), (“une”, “DET”), (“souris”, “NOUN”)].
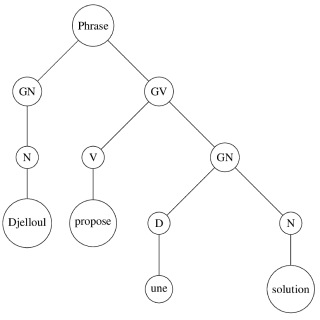
3. L’Analyse syntaxique
L’analyse syntaxique ou parsing consiste à analyser la structure grammaticale d’une phrase pour en extraire sa structure d’arbre syntaxique. Cette analyse aide à comprendre comment les mots sont organisés et reliés entre eux.
La phrase “Le chat mange une souris” peut être représentée par l’arbre syntaxique suivant :
(S (NP (DET Le) (NOUN chat)) (VP (VERB mange) (NP (DET une) (NOUN souris))))4. La lemmatisation et le stemming
La lemmatisation et le stemming sont des techniques utilisées pour réduire les mots à leur forme de base ou racine. La lemmatisation tient compte du contexte pour obtenir la forme canonique correcte, tandis que le stemming coupe simplement les suffixes pour obtenir la racine.
- Stemming : “mangeant” → “mange”
- Lemmatisation : “mangeait” → “manger”
5. Les embeddings de mots
Les embeddings de mots sont des représentations vectorielles des mots qui capturent leurs significations et relations sémantiques. Des modèles comme Word2Vec, GloVe et FastText sont couramment utilisés pour générer ces embeddings.
Le mot “roi” et “reine” peuvent être représentés dans un espace vectoriel de telle sorte que les relations sémantiques et analogiques soient préservées. Par exemple, l’opération vectorielle “roi – homme + femme” donne un vecteur proche de celui de “reine”.
6. Les modèles de langage
Les modèles de langage prédisent la probabilité d’une séquence de mots et sont essentiels pour des tâches comme la génération de texte et la traduction automatique. Les modèles récents, comme ceux basés sur les transformeurs (BERT, GPT-4o, Gemini, LLama, Claude Opus/Sonnet, Mixtral), ont révolutionné le NLP par leur capacité à comprendre et générer du texte de manière plus contextuelle et cohérente.
2023 a été une année folle dans ce secteur, mais 2024 s’annonce digne des plus grandes œuvres de science-fiction ! Attachez vos ceintures, car les avancées en NLP promettent de repousser encore plus loin les limites de l’imagination.
Les techniques de base pour analyser le langage
Maintenant que nous avons couvert les concepts fondamentaux, explorons quelques techniques de base utilisées dans le NLP.
1. La vectorisation des textes
Avant d’appliquer des algorithmes de machine learning sur des données textuelles, il est nécessaire de les convertir en une forme numérique. Plusieurs techniques sont utilisées pour cela :
- Bag of Words (BoW) : Représente les textes comme des vecteurs de fréquences de mots.
- TF-IDF (Term Frequency-Inverse Document Frequency) : Pondère les mots en fonction de leur fréquence dans un document et leur rareté dans l’ensemble des documents.
- Embeddings de Mots : Utilise des représentations vectorielles denses pour capturer la signification des mots.
2. Les classificateurs de texte
Les classificateurs de texte sont utilisés pour catégoriser automatiquement des textes en fonction de leur contenu. Les algorithmes couramment utilisés incluent :
- Régression logistique : Simple et efficace pour des problèmes de classification binaire.
- Machines à vecteurs de support (SVM) : Performantes pour les tâches de classification avec un petit nombre de caractéristiques.
- Naive Bayes : Particulièrement efficace pour les tâches de classification de texte en raison de sa simplicité et de ses performances sur des données textuelles.
3. La Reconnaissance d’Entités Nommées (NER)
La NER consiste à identifier et classifier les entités nommées (personnes, organisations, lieux, etc.) dans un texte. Cette technique est essentielle pour l’extraction d’informations et l’analyse de texte.
Dans la phrase “Google a annoncé l’ouverture d’un nouveau bureau à Paris”, la NER identifierait :
- Google : Organisation
- Paris : Lieu
4. Les modèles Séquence-à-Séquence
Les modèles séquence-à-séquence (Seq2Seq) sont utilisés pour des tâches où une séquence d’entrée doit être transformée en une séquence de sortie, comme la traduction automatique et le résumé de texte. Ces modèles utilisent des encodeurs-décodeurs pour traiter les séquences.
Pour traduire la phrase “Comment ça va ?” en anglais, un modèle Seq2Seq peut produire “How are you?”.
5. Les Réseaux de Neurones Récurrents (RNN) et LSTM
Les RNN et leurs variantes comme les LSTM (Long Short-Term Memory) sont utilisés pour traiter des données séquentielles en raison de leur capacité à conserver des informations contextuelles sur de longues séquences. Ils sont particulièrement efficaces pour les tâches de modélisation de séquences.
Un LSTM peut être utilisé pour prédire la prochaine phrase dans un dialogue basé sur les phrases précédentes.
Les modèles NLP qui se démarquent dans la course de l’IA
L’avènement des modèles basés sur les transformeurs a transformé le domaine du NLP, offrant des performances inégalées sur diverses tâches de traitement du langage naturel.
1. BERT (Bidirectional Encoder Representations from Transformers)
BERT est un modèle de langage pré-entraîné qui utilise des transformeurs bidirectionnels pour comprendre le contexte des mots dans les phrases. Il a établi de nouveaux standards pour de nombreuses tâches NLP.
Quelles sont ses particularités ?
- Pré-entrainement bidirectionnel : BERT considère le contexte des deux côtés d’un mot dans une phrase, ce qui améliore la compréhension contextuelle.
- Fine-tuning : BERT peut être ajusté pour des tâches spécifiques comme la classification de texte, la NER et la réponse à des questions.
2. GPT (Generative Pre-trained Transformer)
GPT, et plus particulièrement GPT-3, est un modèle de langage génératif qui utilise des transformeurs pour générer du texte de manière cohérente et contextuelle. GPT-3 est connu pour sa capacité à comprendre et générer du texte à un niveau impressionnant.
Quelles sont ses particularités ?
- Génération de texte : GPT-3 peut générer des paragraphes de texte de manière autonome à partir d’une simple phrase ou d’un prompt.
- Applications variées : Utilisé pour la rédaction automatique, la création de contenu, le chatbots et bien plus encore.
3. Transformer-XL et XLNet
Transformer-XL et XLNet sont des variantes des modèles de transformeurs qui améliorent les capacités des modèles traditionnels en permettant de traiter des séquences plus longues et en offrant une meilleure compréhension contextuelle.
Quelles sont ses particularités ?
- Transformer-XL : Gère les dépendances à long terme mieux que les transformeurs classiques grâce à un mécanisme de mémoire segmentée.
- XLNet : Combine les avantages de BERT et des modèles autoregressifs pour une meilleure performance sur diverses tâches NLP.
Les Défis et Opportunités du NLP
Le domaine du NLP est en constante évolution, avec de nombreux défis et opportunités à explorer.
Défis
- Compréhension contextuelle : Bien que les modèles avancés aient fait des progrès significatifs, la compréhension fine du contexte reste un défi.
- Biais dans les données : Les modèles NLP peuvent reproduire et amplifier les biais présents dans les données d’entraînement.
- Ambiguïté linguistique : Les langues naturelles sont intrinsèquement ambiguës, rendant difficile pour les modèles de saisir toutes les nuances.
Opportunités
- Multilinguisme : Développer des modèles capables de traiter plusieurs langues avec la même efficacité.
- Applications innovantes : Utilisation du NLP dans des domaines émergents comme la médecine, le droit, et l’éducation.
- Interactions Homme-Machine : Améliorer les interactions naturelles entre humains et machines pour des applications plus intuitives.
Le Traitement du Langage Naturel est un domaine fascinant et dynamique de l’intelligence artificielle, avec des applications qui touchent presque tous les aspects de notre vie quotidienne. De la compréhension contextuelle à la génération de texte, les avancées en NLP continuent de transformer la manière dont nous interagissons avec la technologie.
Alors, êtes-vous prêt à plonger plus profondément dans le monde du NLP et à explorer ses vastes possibilités ? Que l’exploration commence !