
Bonjour à vous, explorateurs des langages formels ! Aujourd’hui, nous nous embarquons dans un voyage fascinant au cœur de l’analyse syntaxique. Ce domaine, à l’intersection de la linguistique et de l’informatique, joue un rôle crucial dans le traitement des langages formels et naturels.
Êtes-vous prêts à découvrir comment les machines comprennent et structurent nos langues ? Accrochez-vous, car nous allons plonger dans les profondeurs de l’analyse syntaxique, où chaque mot, chaque syntagme et chaque phrase prennent une signification précise et rigoureuse. Que l’aventure commence !
Qu’est-ce que l’analyse syntaxique ?
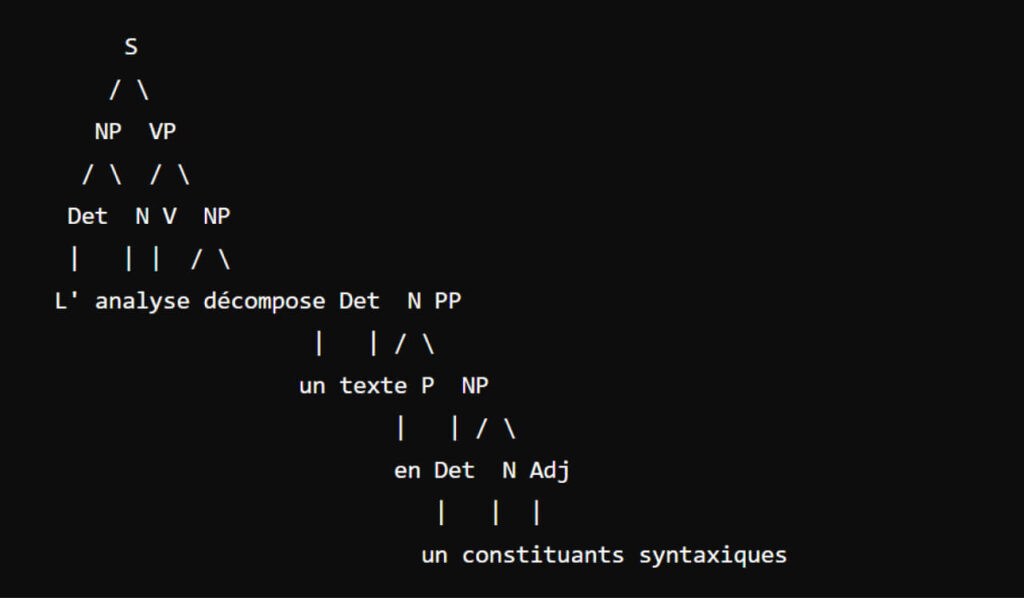
L’analyse syntaxique, ou parsing, est le processus par lequel un programme informatique décompose un texte en ses constituants syntaxiques pour vérifier sa structure et en extraire des informations. Cela implique d’examiner un texte selon les règles d’une grammaire formelle spécifique. Les applications de l’analyse syntaxique sont nombreuses, allant de la compilation des langages de programmation à la compréhension des langues naturelles.
Analyseur syntaxique (parser)
Un analyseur syntaxique, ou parser, est un programme informatique qui analyse la structure grammaticale d’une entrée donnée selon une grammaire formelle. Il transforme une séquence de lexèmes, issus de l’analyse lexicale, en un arbre syntaxique qui représente la hiérarchie des syntagmes.
Langage formel et grammaire formelle
Un langage formel est un ensemble de chaînes de symboles régies par des règles spécifiques, appelées grammaires formelles. Une grammaire formelle définit la syntaxe correcte d’un langage à travers un ensemble de productions ou règles de réécriture.
Arbre syntaxique pour la phrase : 'L'analyse syntaxique décompose un texte en constituants syntaxiques.'
S
/ \
NP VP
/ \ / \
Det N V NP
| | | / \
L' analyse décompose Det N PP
| | / \
un texte P NP
| | / \
en Det N Adj
| | |
un constituants syntaxiquesMaintenant, si nous voulons définir un langage simple pour des expressions arithmétiques, nous allons créer un langage formel pour des expressions arithmétiques simples comportant des additions et des multiplications. Voici comment nous pourrions définir une grammaire formelle pour ce langage :
- Symboles terminaux : Ce sont les éléments de base du langage (par exemple, les chiffres et les opérateurs).
- Chiffres :
0, 1, 2, 3, 4, 5, 6, 7, 8, 9 - Opérateurs :
+(addition),*(multiplication)
- Chiffres :
- Symboles non terminaux : Ce sont des variables qui représentent des groupes de symboles terminaux ou d’autres symboles non terminaux.
E(expression)T(terme)F(facteur)
- Règles de production : Ce sont des règles qui définissent comment les symboles non terminaux peuvent être remplacés par des symboles terminaux ou d’autres symboles non terminaux.
E -> E + T | T(une expression est soit une expression suivie d’un + et d’un terme, soit un terme)T -> T * F | F(un terme est soit un terme suivi d’un * et d’un facteur, soit un facteur)F -> ( E ) | chiffre(un facteur est soit une expression entre parenthèses, soit un chiffre)
- Symbole de départ : Le symbole à partir duquel la dérivation commence.
- Symbole de départ :
E
- Symbole de départ :
Exemple de dérivation
Voyons comment cette grammaire permet de dériver une expression arithmétique comme 3 + 5 * 2.
- Commencer par le symbole de départ :
E - Appliquer la première règle de production
(E -> E + T) : E -> E + T - Remplacer E par T (selon la deuxième partie de la première règle) :
E + T -> T + T - Remplacer chaque T par F (en utilisant
T -> F) :T + T -> F + T - Appliquer
T -> T * F : T + T -> F + T * F - Remplacer les facteurs par des chiffres :
F + T -> 3 + T et T * F -> 5 * F - Remplacer les derniers facteurs par des chiffres :
F -> 2
Finalement, nous obtenons :
E -> T + T -> F + T -> 3 + T -> 3 + T * F -> 3 + 5 * F -> 3 + 5 * 2
Cette séquence de remplacements montre comment la grammaire formelle génère l’expression 3 + 5 * 2.
Syntagmes et arbre syntaxique
Les syntagmes sont des groupes de mots qui forment des unités syntaxiques. Un arbre syntaxique est une représentation arborescente de la structure d’une phrase selon les règles d’une grammaire formelle. Chaque nœud de l’arbre correspond à un syntagme ou une règle grammaticale appliquée.
Les différents rôles et types d’analyseurs syntaxiques
L’analyse syntaxique joue des rôles variés et utilise différents types de parseurs pour accomplir ses tâches.
Analyseurs descendants et ascendants
Les analyseurs se classent principalement en deux types : descendants et ascendants.
Analyseurs descendants
Les analyseurs descendants commencent par les règles de haut niveau de la grammaire et décomposent la phrase en éléments de plus en plus petits. Ils incluent les analyseurs LL, qui lisent l’entrée de gauche à droite et produisent une analyse de gauche à droite.
Analyseurs ascendants
Les analyseurs ascendants commencent par les éléments de base et construisent des structures de plus en plus complexes jusqu’à obtenir la phrase complète. L’analyse LR est un exemple typique de cette méthode, souvent utilisée dans les compilateurs modernes.
Méthodes tabulaires et retour sur trace
Certains parseurs utilisent des méthodes spécifiques pour gérer des grammaires plus complexes ou optimiser les performances.
Méthodes tabulaires
Les méthodes tabulaires, comme l’analyse CYK (Cocke-Younger-Kasami), utilisent des tableaux pour mémoriser les sous-problèmes déjà résolus, ce qui permet de rendre l’analyse syntaxique plus efficace.
Retour sur trace
Le retour sur trace (backtracking) est une technique utilisée par certains parseurs pour explorer différentes possibilités d’analyse syntaxique et revenir en arrière si une certaine branche d’analyse échoue.
Analyseurs spécialisés
Certains parseurs sont spécialisés pour des usages particuliers, tels que les grammaires d’arbres adjoints (TAG) pour les langues naturelles et les automates à pile pour les grammaires non contextuelles.
Comment réaliser l’analyse syntaxique d’une phrase ou d’un texte en 5 étapes
Pour bien comprendre comment fonctionne l’analyse syntaxique, décomposons le processus de parsing en étapes claires et précises. Dans cette section, nous allons développer chaque étape en détail, illustrer le processus avec des exemples pratiques en Python et intégrer des modèles NLP (Natural Language Processing) courrants.
Étape 1 : Analyse lexicale
L’analyse lexicale est la première étape, où le texte est décomposé en unités significatives appelées lexèmes. Un analyseur lexical scanne la chaîne de caractères et identifie les mots et symboles. Cette étape est essentielle car elle prépare les données pour les étapes suivantes de l’analyse syntaxique.
Implémentation en Python :
Pour cette étape, nous pouvons utiliser la bibliothèque NLTK (Natural Language Toolkit) de Python, qui fournit des outils pour l’analyse lexicale.
import nltk
nltk.download('punkt')
def analyse_lexicale(texte):
lexemes = nltk.word_tokenize(texte)
return lexemes
texte = "Le chat mange la souris."
lexemes = analyse_lexicale(texte)
print(lexemes)
Dans cet exemple, le tokenizer nltk.word_tokenize est utilisé pour diviser le texte en lexèmes. Les résultats montrent une liste de mots individuels et de symboles, qui seront utilisés pour la construction de l’arbre syntaxique.
Étape 2 : Construction de l’arbre syntaxique
Ensuite, le parser utilise les lexèmes pour construire un arbre syntaxique. Cet arbre représente la structure hiérarchique des syntagmes selon les règles de la grammaire formelle. Les syntagmes sont des groupes de mots qui forment des unités syntaxiques, comme des phrases nominales ou verbales.
Implémentation en Python :
Pour cette étape, nous utiliserons les capacités de NLTK pour créer des arbres syntaxiques.
from nltk import CFG
grammaire = CFG.fromstring("""
S -> NP VP
NP -> DT N
VP -> V NP
DT -> 'Le'
N -> 'chat' | 'souris'
V -> 'mange'
""")
from nltk.parse.generate import generate
def construire_arbre_syntaxique(grammaire, lexemes):
parser = nltk.ChartParser(grammaire)
for tree in parser.parse(lexemes):
return tree
lexemes = ['Le', 'chat', 'mange', 'la', 'souris']
arbre_syntaxique = construire_arbre_syntaxique(grammaire, lexemes)
arbre_syntaxique.pretty_print()
Dans cet exemple, nous définissons une grammaire formelle simple utilisant une grammaire hors-contexte (CFG) pour générer et analyser la structure syntaxique.
Étape 3 : Analyse sémantique
Une fois l’arbre syntaxique construit, l’étape suivante est l’analyse sémantique, où la signification des structures syntaxiques est vérifiée pour s’assurer qu’elles sont sémantiquement cohérentes. Cela implique l’association des syntagmes et des lexèmes à leurs rôles sémantiques dans la phrase.
Implémentation en Python :
Nous pouvons utiliser des modèles NLP pour effectuer une analyse sémantique. Par exemple, spaCy est une bibliothèque NLP en Python qui offre des outils puissants pour cette tâche.
import spacy
nlp = spacy.load('fr_core_news_sm')
def analyse_semantique(texte):
doc = nlp(texte)
for token in doc:
print(f'{token.text} -> {token.dep_}')
texte = "Le chat mange la souris."
analyse_semantique(texte)
Cet exemple montre comment utiliser spaCy pour analyser les rôles sémantiques des mots dans une phrase. Chaque mot est associé à sa dépendance syntaxique (e.g., sujet, objet).
Étape 4 : Optimisation et erreurs
L’optimisation et la gestion des erreurs sont des étapes critiques. Les techniques comme le mode panique permettent de gérer les erreurs syntaxiques en ignorant une partie de l’entrée jusqu’à trouver un point où l’analyse peut reprendre en toute sécurité. L’optimisation implique également l’utilisation de structures de données efficaces et l’amélioration des algorithmes pour accélérer le processus d’analyse.
Implémentation en Python :
Lors de l’analyse syntaxique, il est important de détecter et de corriger les erreurs syntaxiques. Par exemple, si une phrase contient un mot inconnu ou une structure incorrecte, le parser doit être capable de gérer ces situations.
from nltk.parse.generate import generate
def gestion_erreurs(grammaire, lexemes):
try:
arbre_syntaxique = construire_arbre_syntaxique(grammaire, lexemes)
arbre_syntaxique.pretty_print()
except ValueError as e:
print(f"Erreur détectée: {e}")
# Mode panique: Ignorer une partie de l'entrée
lexemes = lexemes[:-1]
gestion_erreurs(grammaire, lexemes)
lexemes_errone = ['Le', 'chat', 'mange', 'la']
gestion_erreurs(grammaire, lexemes_errone)
Cet exemple montre comment implémenter une gestion des erreurs simple en utilisant le mode panique.
Étape 5 : Génération de la sortie
Enfin, le résultat de l’analyse syntaxique est utilisé pour générer une sortie, telle que le code machine dans le cas des compilateurs, ou une représentation sémantique pour les applications de traitement des langues naturelles.
Implémentation en Python :
Pour illustrer cette étape, nous allons générer une représentation sémantique simple à partir de l’arbre syntaxique construit.
def generer_sortie_semantique(arbre_syntaxique):
sortie = []
for subtree in arbre_syntaxique.subtrees():
if subtree.label() == 'VP':
sortie.append(f"Action: {subtree[0][0]}")
elif subtree.label() == 'NP':
sortie.append(f"Objet: {' '.join(word for word, pos in subtree.leaves())}")
return sortie
sortie_semantique = generer_sortie_semantique(arbre_syntaxique)
print(sortie_semantique)
Cet exemple extrait les actions et objets de l’arbre syntaxique pour produire une sortie sémantique simple.
Application avancée avec des modèles NLP
Pour aller plus loin, nous pouvons utiliser des modèles de langage avancés pour effectuer des analyses plus complexes. Par exemple, les modèles de type Transformer comme BERT ou GPT-3 offrent des capacités de compréhension du langage naturel de pointe.
Implémentation en Python avec Transformers
Nous utiliserons la bibliothèque Transformers de Hugging Face pour démontrer une analyse syntaxique avancée.
from transformers import pipeline
analyseur = pipeline("ner", model="dbmdz/bert-large-cased-finetuned-conll03-english")
def analyse_avancee(texte):
resultats = analyseur(texte)
return resultats
texte = "Le chat mange la souris."
resultats = analyse_avancee(texte)
print(resultats)
Dans cet exemple, nous utilisons un modèle pré-entraîné pour effectuer une analyse des entités nommées (NER), ce qui fait partie de l’analyse sémantique avancée.
Pour bien comprendre et maîtriser l’analyse syntaxique, il est crucial de suivre ces étapes méthodiques : analyse lexicale, construction de l’arbre syntaxique, analyse sémantique, gestion des erreurs et génération de la sortie. En utilisant des outils et des bibliothèques comme NLTK, spaCy et Transformers, nous pouvons implémenter et optimiser ces étapes en Python pour diverses applications, de la compilation de code au traitement avancé des langues naturelles. Continuez à explorer et à expérimenter ces techniques pour enrichir vos compétences en analyse syntaxique et NLP !
Les applications de l’analyse syntaxique
Les compilateurs en programmation
Les compilateurs sont des programmes qui traduisent le code source écrit dans un langage de programmation en code machine exécutable. L’analyse syntaxique est une étape cruciale dans ce processus, où le compilateur vérifie la structure syntaxique du code source.
Traitement des langues naturelles
L’analyse syntaxique est également essentielle dans le traitement des langues naturelles (NLP), où elle aide à comprendre et à interpréter les structures grammaticales des phrases en langage naturel.
Grammaires d’arbres adjoints (TAG)
Les grammaires d’arbres adjoints (TAG) sont une forme de grammaire formelle utilisée dans le NLP pour modéliser les structures syntaxiques complexes des langues naturelles.
Automate à pile
Un automate à pile est une machine théorique utilisée pour modéliser les langages algébriques et les grammaires non contextuelles. Il joue un rôle clé dans certains types d’analyse syntaxique.
Techniques avancées et concepts complémentaires pour aller plus loin
Analyse LL et LR : une comparaison
L’analyse LL est plus simple à implémenter et est bien adaptée aux grammaires moins complexes. Elle fonctionne en partant du sommet de l’arbre syntaxique et en allant vers les feuilles. En revanche, l’analyse LR est plus puissante et peut gérer des grammaires plus complexes. Elle part des feuilles de l’arbre syntaxique pour remonter vers la racine.
Automates à pile
Les automates à pile sont des machines théoriques qui utilisent une pile pour gérer les opérations. Ils sont particulièrement utiles pour analyser les grammaires non contextuelles, qui nécessitent la gestion de hiérarchies de syntagmes.
Méthodes d’analyse tabulaires
Les méthodes d’analyse tabulaires, comme l’algorithme CYK, utilisent des tableaux pour stocker les résultats intermédiaires de l’analyse syntaxique. Cela permet de gérer efficacement les redondances et d’améliorer les performances des parseurs.
Grammaires d’arbres adjoints (TAG)
Les grammaires d’arbres adjoints (TAG) sont une extension des grammaires contextuelles qui permettent de modéliser des structures syntaxiques plus complexes. Elles sont utilisées pour représenter des phrases avec des relations de dépendance longues et des constructions syntaxiques imbriquées.
Analyse pragmatique
L’analyse pragmatique se concentre sur l’utilisation du langage dans des contextes spécifiques. Elle examine comment les locuteurs utilisent le langage pour accomplir des actions, influencer les autres et naviguer dans des interactions sociales.
Illustrations concrètes
Exemple d’analyse syntaxique en FORTRAN
Prenons un exemple simple de code en FORTRAN :
fortranCopier le code
PROGRAM HelloWorld
PRINT *, 'Hello, World!'
END PROGRAM HelloWorld
- Analyse lexicale : Le code est d’abord décomposé en lexèmes tels que
PROGRAM,PRINT, “, etEND. - Analyse syntaxique : Un parser vérifie la structure du programme selon les règles de la grammaire FORTRAN. Il construit un arbre syntaxique représentant la hiérarchie des syntagmes.
- Analyse sémantique : Le code est ensuite vérifié pour s’assurer qu’il est sémantiquement correct, c’est-à-dire que les opérations et les instructions font sens dans le contexte du programme.
Exemple d’analyse syntaxique en Prolog
Considérons une règle simple en Prolog :
prologCopier le code
likes(mary, chocolate).
- Analyse lexicale : Le texte est décomposé en lexèmes :
likes,mary,chocolate. - Analyse syntaxique : Le parser construit un arbre syntaxique représentant la structure de la règle. Chaque lexème est identifié et placé dans l’arborescence.
- Analyse sémantique : La règle est ensuite vérifiée pour s’assurer qu’elle respecte les règles sémantiques de Prolog.
Exemple d’analyse syntaxique en traitement des langues naturelles
Considérons la phrase suivante :
Copier le code
Le chat mange la souris.
- Analyse lexicale : La phrase est décomposée en lexèmes :
Le,chat,mange,la,souris. - Analyse syntaxique : Un parser construit un arbre syntaxique où
Le chatest un syntagme nominal (SN) etmange la sourisest un syntagme verbal (SV). - Analyse sémantique : La phrase est analysée pour vérifier qu’elle a du sens. Par exemple,
chatetsourissont des noms communs qui peuvent entrer dans une relation prédateur-proie.
Gestion des erreurs
Mode panique
Le mode panique est une stratégie utilisée par les parseurs pour gérer les erreurs syntaxiques en ignorant une partie de l’entrée jusqu’à trouver un point où l’analyse peut reprendre en toute sécurité.
Productions erreurs et corrections
Les productions erreurs sont des règles supplémentaires dans une grammaire qui permettent de reconnaître et de corriger certaines erreurs syntaxiques courantes. La correction locale tente de corriger les erreurs immédiatement, tandis que la correction globale recherche des solutions optimales à l’échelle de l’ensemble du texte.
Psycholinguistique et langues naturelles
Diagrammes de phrases
Les diagrammes de phrases sont des représentations visuelles des structures syntaxiques des phrases, souvent utilisées dans l’enseignement de la grammaire et de la linguistique.
Connotation et pragmatique
L’analyse pragmatique va au-delà de la syntaxe et de la sémantique pour examiner comment les contextes et les situations influencent le sens et l’interprétation des phrases. La connotation, quant à elle, s’intéresse aux significations implicites et aux associations émotionnelles des mots.
L’analyse syntaxique est une discipline fondamentale qui permet de comprendre et de structurer les langages formels et naturels. Des algorithmes sophistiqués et des techniques avancées permettent aux ordinateurs de décomposer, analyser et comprendre des textes de manière précise et efficace. Que ce soit pour compiler des programmes ou traiter des langues naturelles, l’analyse syntaxique est au cœur de nombreuses applications informatiques. Alors, chers explorateurs des langages, continuez à plonger dans ce monde fascinant et à découvrir les merveilles de la structure syntaxique. Que vos aventures syntaxiques soient riches en découvertes et en apprentissages !